1. 트리 (Tree) 구조
- 트리: Node와 Branch를 이용해서, 사이클을 이루지 않도록 구성한 데이터 구조
- 실제로 어디에 많이 사용되나?
- 트리 중 이진 트리 (Binary Tree) 형태의 구조로, 탐색(검색) 알고리즘 구현을 위해 많이 사용됨
2. 알아둘 용어
- Node: 트리에서 데이터를 저장하는 기본 요소 (데이터와 다른 연결된 노드에 대한 Branch 정보 포함)
- Root Node: 트리 맨 위에 있는 노드
- Level: 최상위 노드를 Level 0으로 하였을 때, 하위 Branch로 연결된 노드의 깊이를 나타냄
- Parent Node: 어떤 노드의 다음 레벨에 연결된 노드
- Child Node: 어떤 노드의 상위 레벨에 연결된 노드
- Leaf Node (Terminal Node): Child Node가 하나도 없는 노드
- Sibling (Brother Node): 동일한 Parent Node를 가진 노드
- Depth: 트리에서 Node가 가질 수 있는 최대 Level

3. 이진 트리와 이진 탐색 트리 (Binary Search Tree)
- 이진 트리: 노드의 최대 Branch가 2인 트리
- 이진 탐색 트리 (Binary Search Tree, BST): 이진 트리에 다음과 같은 추가적인 조건이 있는 트리
- 왼쪽 노드는 해당 노드보다 작은 값, 오른쪽 노드는 해당 노드보다 큰 값을 가지고 있음!

4. 자료 구조 이진 탐색 트리의 장점과 주요 용도
- 주요 용도: 데이터 검색(탐색)
- 장점: 탐색 속도를 개선할 수 있음
단점은 이진 탐색 트리 알고리즘 이해 후에 살펴보기로 함
이진트리와 정렬된 배열간의 탐색 비교

5. 파이썬 객체지향 프로그래밍으로 링크드 리스트 구현하기
5.1. 노드 클래스 만들기

왼쪽 브랜치와 오른쪽 브랜치를 left, right로 구분
5.2. 이진 탐색 트리에 데이터 넣기
- 이진 탐색 트리 조건에 부합하게 데이터를 넣어야 함

value가 현재 노드보다 작을 경우 왼쪽이 비었으면 left에 Node(value) 저장
값이 있을 경우 왼쪽 노드로 이동해서 반복
value가 현재 노드보다 클 경우 오른쪽이 비었으면 right에 Node(value) 저장
값이 있을 경우 오른쪽 노드로 이동해서 반복

이진 탐색 트리의 탐색 메서드
현재 노드값이 찾는 값과 같으면 True 반환
찾는 값이 현재 노드값보다 작으면 왼쪽 노드로 이동
찾느값이 현재 노드값보다 크면 오른쪽 노드로 이동

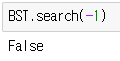
트리에 있는 값은 True 없는 값은 False를 반환하는 모습
5.4. 이진 탐색 트리 삭제
- 매우 복잡함. 경우를 나누어서 이해하는 것이 좋음
5.4.1. Leaf Node 삭제
- Leaf Node: Child Node 가 없는 Node
- 삭제할 Node의 Parent Node가 삭제할 Node를 가리키지 않도록 한다.

5.4.2. Child Node 가 하나인 Node 삭제
- 삭제할 Node의 Parent Node가 삭제할 Node의 Child Node를 가리키도록 한다.

5.4.3. Child Node 가 두 개인 Node 삭제
- 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
- 삭제할 Node의 왼쪽 자식 중, 가장 큰 값을 삭제할 Node의 Parent Node가 가리키도록 한다.

5.4.3.1. 삭제할 Node의 오른쪽 자식중, 가장 작은 값을 삭제할 Node의 Parent Node가 가리키게 할 경우
- 삭제할 Node의 오른쪽 자식 선택
- 오른쪽 자식의 가장 왼쪽에 있는 Node를 선택
- 해당 Node를 삭제할 Node의 Parent Node의 왼쪽 Branch가 가리키게 함
- 해당 Node의 왼쪽 Branch가 삭제할 Node의 왼쪽 Child Node를 가리키게 함
- 해당 Node의 오른쪽 Branch가 삭제할 Node의 오른쪽 Child Node를 가리키게 함
- 만약 해당 Node가 오른쪽 Child Node를 가지고 있었을 경우에는, 해당 Node의 본래 Parent Node의 왼쪽 Branch가 해당 오른쪽 Child Node를 가리키게 함
5.5. 이진 탐색 트리 삭제 코드 구현과 분석
5.5.1 삭제할 Node 탐색
- 삭제할 Node가 없는 경우도 처리해야 함
- 이를 위해 삭제할 Node가 없는 경우는 False를 리턴하고, 함수를 종료 시킴

삭제하기 전 트리에 삭제할 value가 있는지 확인하기 위해 searched 변수를 만들고
current_node.value 와 value가 같으면 True 반환
value가 current_node.value보다 작으면 self.parent에 self.current_node 넣고 self.current_node에는 left값 넣는다.
value가 current_node.value보다 크면 self.parent에 self.current_node 넣고 self.current_node에는 right값 넣는다.
5.5.3. Case3-1: 삭제할 Node가 Child Node를 두 개 가지고 있을 경우 (삭제할 Node가 Parent Node 왼쪽에 있을 때)
- 기본 사용 가능 전략
- 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
- 삭제할 Node의 왼쪽 자식 중, 가장 큰 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
- 기본 사용 가능 전략 중, 1번 전략을 사용하여 코드를 구현하기로 함
- 경우의 수가 또다시 두가지가 있음
- Case3-1-1: 삭제할 Node가 Parent Node의 왼쪽에 있고, 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 가진 Node의 Child Node가 없을 때
- Case3-1-2: 삭제할 Node가 Parent Node의 왼쪽에 있고, 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 가진 Node의 오른쪽에 Child Node가 있을 때
- 가장 작은 값을 가진 Node의 Child Node가 왼쪽에 있을 경우는 없음, 왜냐하면 왼쪽 Node가 있다는 것은 해당 Node보다 더 작은 값을 가진 Node가 있다는 뜻이기 때문임
- 경우의 수가 또다시 두가지가 있음


currnet_node 와 parent를 찾을 때 처럼 change_node와 change_node_parent를 찾는다.
change_node의 오른쪽에 브랜치가 있을 경우 오른쪽 브랜치를 change_node_parent의 왼쪽 브랜치에 연결한다
없을 경우에는 change_node_parent의 왼쪽 브랜치를 None으로 만들고
change_node를 current_node자리에 넣고 parent의 왼쪽 브랜치에 연결하고
current_node 왼쪽 오른쪽 브랜치와 연결한다
5.5.4. Case3-2: 삭제할 Node가 Child Node를 두 개 가지고 있을 경우 (삭제할 Node가 Parent Node 오른쪽에 있을 때)
- 기본 사용 가능 전략
- 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
- 삭제할 Node의 왼쪽 자식 중, 가장 큰 값을 삭제할 Node의 Parent Node가 가리키도록 한다.
- 기본 사용 가능 전략 중, 1번 전략을 사용하여 코드를 구현하기로 함
- 경우의 수가 또다시 두가지가 있음
- Case3-2-1: 삭제할 Node가 Parent Node의 오른쪽에 있고, 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 가진 Node의 Child Node가 없을 때
- Case3-2-2: 삭제할 Node가 Parent Node의 오른쪽에 있고, 삭제할 Node의 오른쪽 자식 중, 가장 작은 값을 가진 Node의 오른쪽에 Child Node가 있을 때
- 가장 작은 값을 가진 Node의 Child Node가 왼쪽에 있을 경우는 없음, 왜냐하면 왼쪽 Node가 있다는 것은 해당 Node보다 더 작은 값을 가진 Node가 있다는 뜻이기 때문임
- 경우의 수가 또다시 두가지가 있음
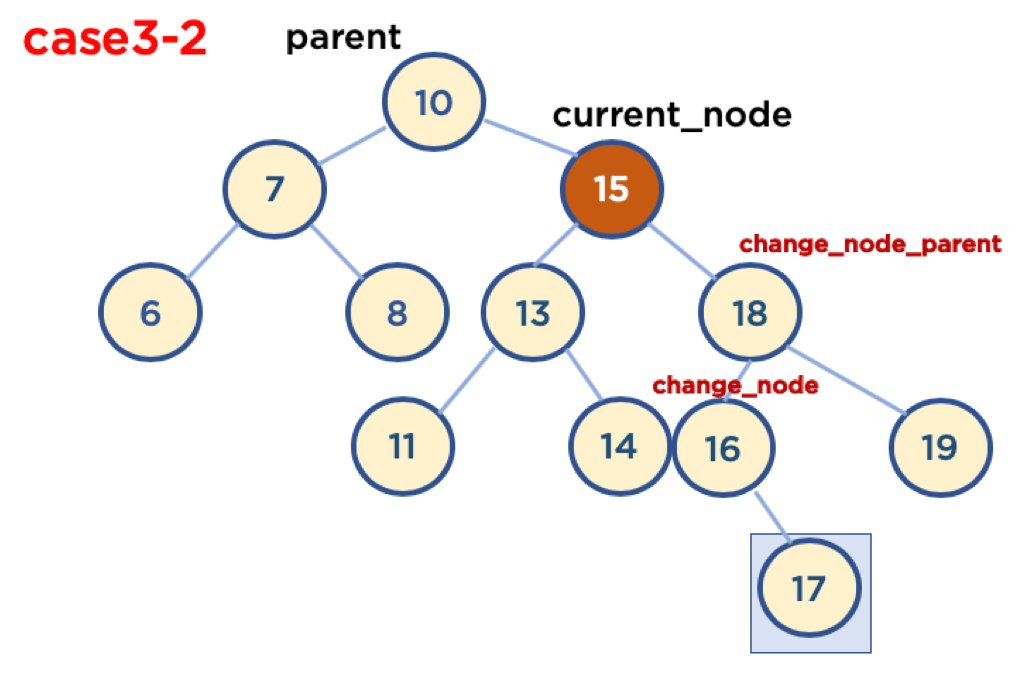

왼쪽에 있을 때와 거의 동일하지만 parent의 오른쪽에 있기 때문에
self.parent.right = self.change_node로 오른쪽에 연결
5.5.6. 파이썬 전체 코드 테스트
- random 라이브러리 활용
- random.randint(첫번째 숫자, 마지막 숫자): 첫번째 숫자부터 마지막 숫자 사이에 있는 숫자를 랜덤하게 선택해서 리턴
- 예: random.randint(0, 99): 0에서 99까지 숫자중 특정 숫자를 랜덤하게 선택해서 리턴해줌
- random.randint(첫번째 숫자, 마지막 숫자): 첫번째 숫자부터 마지막 숫자 사이에 있는 숫자를 랜덤하게 선택해서 리턴

검색기능과 삭제기능에서 문제가 있으면 확인할 수 있게 if문 속에 print문 추가
6. 이진 탐색 트리의 시간 복잡도와 단점
6.1. 시간 복잡도 (탐색시)
- depth (트리의 높이) 를 h라고 표기한다면, O(h)
- n개의 노드를 가진다면, ℎ=𝑙𝑜𝑔2𝑛h=log2n 에 가까우므로, 시간 복잡도는 𝑂(𝑙𝑜𝑔𝑛)O(logn)
- 참고: 빅오 표기법에서 𝑙𝑜𝑔𝑛logn 에서의 log의 밑은 10이 아니라, 2입니다.
- 한번 실행시마다, 50%의 실행할 수도 있는 명령을 제거한다는 의미. 즉 50%의 실행시간을 단축시킬 수 있다는 것을 의미함

- 한번 실행시마다, 50%의 실행할 수도 있는 명령을 제거한다는 의미. 즉 50%의 실행시간을 단축시킬 수 있다는 것을 의미함
- 참고: 빅오 표기법에서 𝑙𝑜𝑔𝑛logn 에서의 log의 밑은 10이 아니라, 2입니다.
Type Markdown and LaTeX: 𝛼2α2
6.2. 이진 탐색 트리 단점
- 평균 시간 복잡도는 𝑂(𝑙𝑜𝑔𝑛)O(logn) 이지만,
- 이는 트리가 균형잡혀 있을 때의 평균 시간복잡도이며,
- 다음 예와 같이 구성되어 있을 경우, 최악의 경우는 링크드 리스트등과 동일한 성능을 보여줌 ( 𝑂(𝑛)O(n) )

최악의 경우에는 O(n)의 시간복잡도를 보여주고 이를 해결하기 위해 트리를 양 옆으로 나눠주는 알고리즘도 있다고 한다
'자료구조' 카테고리의 다른 글
| 힙(Heap) (0) | 2022.04.25 |
|---|---|
| 해쉬 테이블 (Hash Table) (0) | 2022.03.29 |
| 알고리즘 복잡도 표현 기법 (0) | 2022.03.24 |
| 링크드리스트(Linked List) (0) | 2022.03.16 |
| 스택(Stack) (0) | 2022.03.09 |



